今まで数年間、Ubuntuで立てたシングルノードのDocker Compose上でMastodonを動かしていたのだが、世の中の流れに合わせてKubernetes上に移動させた。
docker-compose.ymlから自動的にKubernetesのマニフェストファイルに変換してくれるコマンドもあるけども、勉強のために手動で1個ずつ置き換えていった。

PostgreSQLのデータをNFS上に移動する
元々はDocker Composeのローカルストレージ上に置いていたPostgreSQLのデータをNFSの共有ディレクトリに移動させた。
- NFSサーバーでディレクトリを共有する
- 共有ディレクトリ上で新DBを初期化する
- 移行元のDBサーバーでpg_dumpコマンドを用いてデータをエクスポートする
- 新DBでエクスポートしたデータをインポートする
同じCPUアーキテクチャ&バージョンであればDBのデータディレクトリをまるごとNFS上に持って行くだけでもデータベース移行出来るのだが、今回はDBバージョンが異なるのと、このタイミングで複数のDBを統合していたのを用途ごとに分割したかったので、上記のようなエクスポート&インポートを用いている。
このとき、Docker Compose上から書き込んでいたデータが、Kubernetes上のプロセスから読めないエラーメッセージが多発したので、NFSのマウントオプションでバージョン3を使う`mountOptions: nfsvers=3`にして回避した。
※NFSv4のACLベースのアクセス権の考え方に引っかかっていた模様。NFSv3まではrwxビットだけなので。。。
apiVersion: v1
kind: PersistentVolume
metadata:
name: postgres-mstdnblue
annotations:
name: postgres-mstdnblue
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteOnce
mountOptions:
- nfsvers=3
nfs:
server: 192.168.8.253
path: /mnt/tank/share/nfs/k8s/postgres-mstdnblue-data
PV/PVCを作る
NFSv3の共有ディレクトリをPodに引き渡すためのPVCであるが、大規模環境だとサイズや速度などで階層化しつつ均一なボリュームをまとめて作って適切にPVCで引きこむような設計をすると想像する。(その方がストレージ設計者とコンピューティングリソースの提供者の役割分担がはっきりしやすい&下のレイヤーを隠蔽しやすい)
ただ、今回の個人用の環境だとどこにどのデータがあるかはっきりしたほうが良いので、NFSディレクトリの名前とannotationsを1対1で対応させてどのPVがどういうデータを持っていて、それをどのPVCで引きこむのか分かりやすいようにしている。

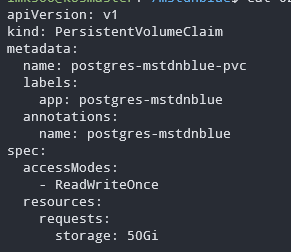
複数のテナントが相乗りするような環境だとPVが再利用されないようにしたり、データの隠匿/暗号化/リサイクル時の確実な消去なども求められるだろうなとも思ったがスルー。
Redisの移行を考える
MastodonのRedis上には他の連合(フェデレーション)を結んでいるサーバーとのトゥートの伝搬等のキューイング情報やジョブ実行状態、ユーザーが最初にアクセスしたときのホームタイムラインなどのキャッシュが保持されている。
今回は御一人様インスタンスでキャッシュやジョブ状態は飛んでしまって構わないとしたので、Redisの情報は引き継いでいかないことにした。
ConfigMapに環境変数を持ち込む
Docker Composeだとini形式(変数名=値が並んだテキストファイル)で各種プロセスに引き渡す環境変数を持っていたが、KubernetesだとConfigMapなりSecretなりにする必要がある。
地道にYAML形式に書き直すことも考えたが、面倒くさかったのでいい手がないか調べたらこんな手順が。
$ kubectl create configmap key-value-sample -n configmap-example --from-env-file=sample.ini上記のコマンドを使ってConfigMapを作成したらenvFromでPodに引き渡すことが出来る。
v1.6 で追加された envFrom
v1.6.0 で下記のように envFrom という項目で ConfigMap または Secret の内容を一度に同名または prefix 付きの環境変数として読み込むことができようになりました。
Kubernetes: ConfigMap / Secret の内容を一度に環境変数として読み込む (envFrom)
https://qiita.com/tkusumi/items/cf7b096972bfa2810800
Mastodonの各種プロセスを起動する
Sidekiq/Streaming/Webのセットはほとんど一緒で、/mastodon/public/systemを共有しながら、bundleなりnodeでプログラムが動いている感じの構成になる。
DeploymentでNFS上のボリュームをマウントしたPodを起動して、外部公開するWebsocketなりHTTPなりのサービスエンドポイントをServiceとして定義してやれば良い。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-mstdnblue
labels:
app: web-mstdnblue
spec:
selector:
matchLabels:
app: web-mstdnblue
strategy:
type: Recreate
template:
metadata:
labels:
app: web-mstdnblue
spec:
hostname: web-mstdnblue
subdomain: local
containers:
- image: tootsuite/mastodon
name: web-mstdnblue
command: ['bash']
args: ['-c','rm -f /mastodon/tmp/pids/server.pid; bundle exec rails s -p 3000 -b 0.0.0.0']
envFrom:
- configMapRef:
name: configmap-mstdnblue
volumeMounts:
- name: mastodon-public-mstdnblue
mountPath: /mastodon/public/system
envFrom:
- configMapRef:
name: configmap-mstdnblue
volumes:
- name: mastodon-public-mstdnblue
persistentVolumeClaim:
claimName: mastodon-public-mstdnblue-pvc
---
apiVersion: v1
kind: Service
metadata:
name: web-mstdnblue
spec:
type: LoadBalancer
selector:
app: web-mstdnblue
ports:
- protocol: TCP
port: 3000
targetPort: 3000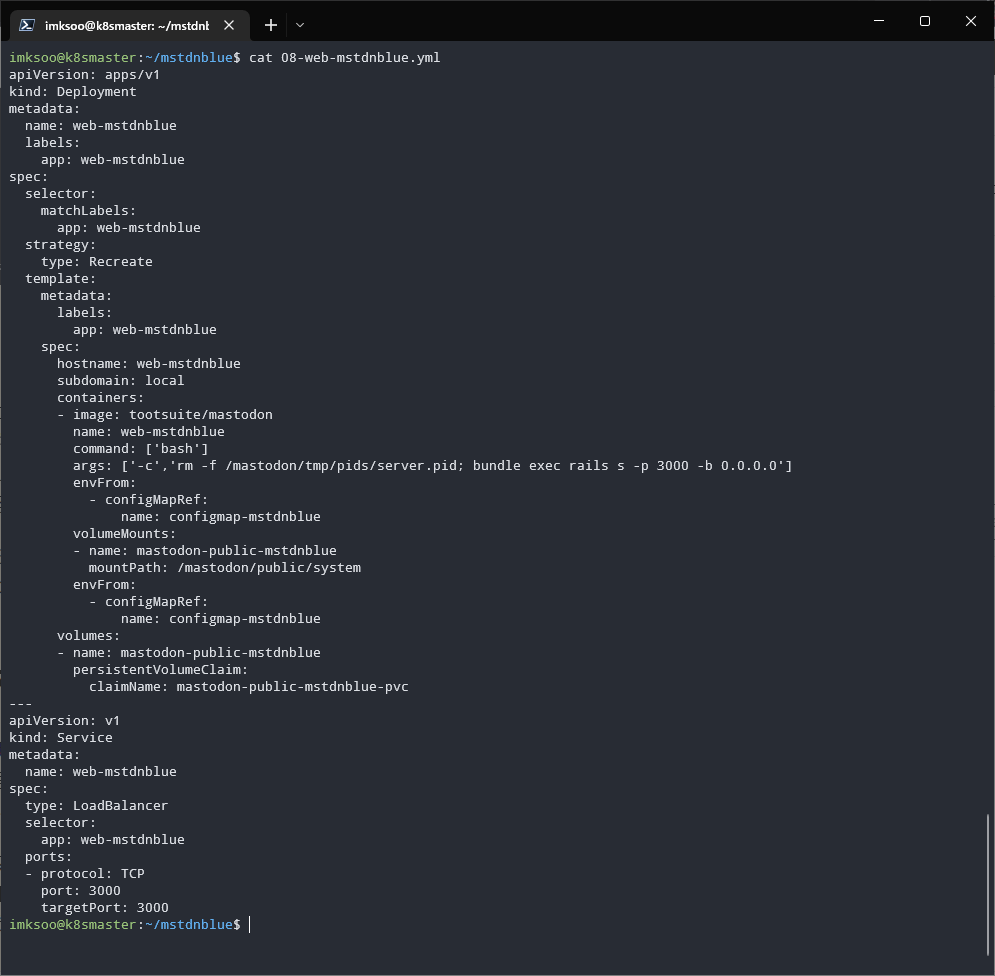
最終的なマニフェスト構成
たぶん、ちゃんとした管理者のいる環境だとPVとPVC あたりに管理者の分担や責任分界線が出てきそう。
それ以外はプロセスの種類ごとに分けてはみたものの、Serviceあたりでアプリケーションエンジニアとネットワークエンジニアの縄張り争いが出そうだなとも思った。

まとめ
Kubernetes環境にアプリケーションを持って行くとしたら、元々Docker前提で綺麗に分かれているものでもそれなりに技量がいる。
もしもレガシーなアプリケーションを持ち込むとしたら作り直した方が早いという言説にも頷ける。
AWS上のALBから、自宅環境のKubernetesクラスターまでトラフィックを持ち込んでいるところはこの記事では省略したがTailscaleを使っていたりする。そのうち書きたい。



